Aquad
The Program for the Analysis of Qualitative Data
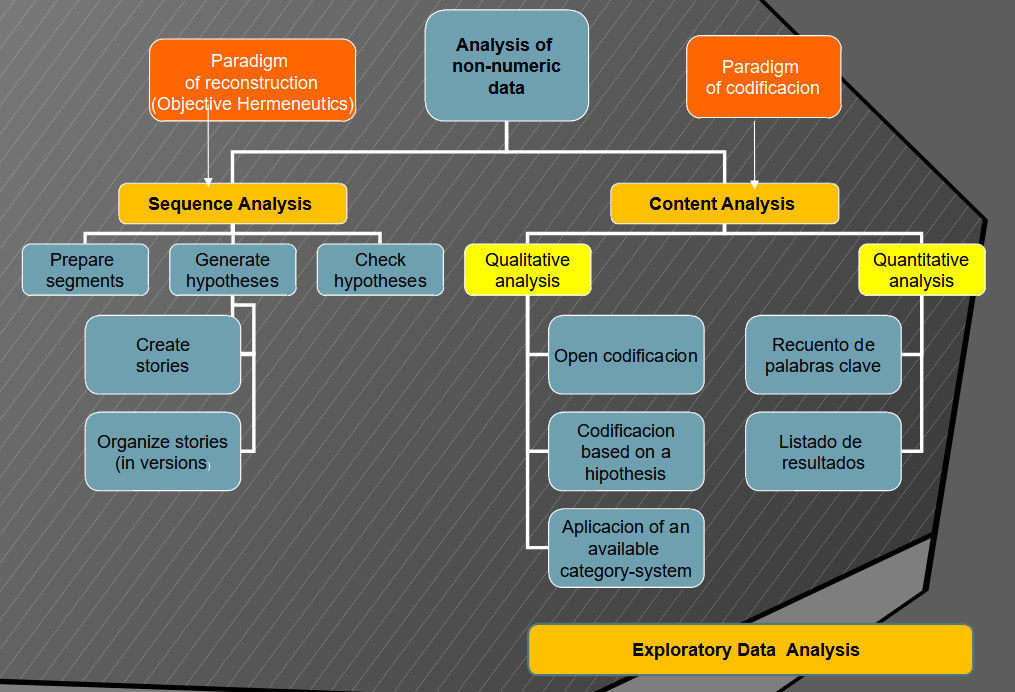 |
Sequence Analysis (Objective Hermeneutics)
| Sequence analysis is a form of analysis of qualitative data, in which one does not start from an overview of the entire text to search for text segments relevant for the research question and code them, but rather in a first phase of hypothesis generation one writes down for each text segment all somehow conceivable meanings. | |
| As text segments AQUAD offers - depending on the type of preparation of the texts - complete sentences, parts of sentences (each up to the next punctuation mark) or word by word freely selected sections. Hypothesis generation is strictly sequential, file segment by file segment. Only if we are convinced that we have created for each of the scrutinized segments all hypotheses relevant to the research question, the rest of the data may be used to confirm or reject each of the noted hypotheses. | |
| In this phase of hypothesis confirmation, we go through the remaining text segments non-sequentially in search of reasons for maintaining or rejecting the previously generated hypotheses. |
Content Analysis: Latent Content
| Following Miles & Huberman (1994) we distinguish in the qualitative content analysis between two interrelated processes, reduction and conclusion. Depending on the methodological approach, reduction follows a more or less structured procedure. The common feature of these procedures is the classification or categorization of text segments. | |
| The designations of the categories are called "codes", the reduction process correspondingly "coding" of the data. | |
| In the process of the conclusion we try to find typical and/or recurring configurations among the codes. For this purpose we can look for typical sequence patterns of codes, look for super- and subordinations of codes, group codes with similar meanings into superordinate categories ("metacodes"), understand codes as poles of a common dimension, or hypothesize or form and test hypotheses about relationships between coded file segments. |
Content Analysis: Manifest Content
| The quantitative content analysis concentrates on manifest text features, i.e. certain key words, idiomatic expressions, metaphors etc. These are searched for and counted. Of interest are the openly accessible, directly ascertainable text elements. | |
| However, the restriction to manifest content is only apparently possible, because in the determination of critical text elements for a quantitative content analysis necessarily qualitative-interpretative assumptions play a central role. We have to decide about which elements refer exactly to critical meanings in the text. in the text. | |
| Ultimately, in a quantitative content analysis, previously (qualitatively!) determined manifest, we have AQUAD count those manifest contents that refer to the latent content, i.e. a particular meaning. As a prerequisite, critical features have to be summarized in a word list before counting them. |